Given three orthographic “napkin sketches” (top, side, front view) of a building, can a deep model produce a detailed 3D model of that architecture? Built a Vision Transformer (DINOv2-based) encoder + custom decoder that maps sketches to triplane representations. Trained on a custom dataset we generated ourselves because nothing existing was good enough.
Designers think in sketches. Three orthographic napkin sketches — top, side, front — capture most of what a building wants to be. We asked whether a 2D-to-3D transformer could produce a detailed 3D model from just those three inputs, and built one to find out: DINOv2 multi-view embeddings, patch fusion, and a custom transformer decoder that outputs triplane features the designer can refine downstream.
This was the 11-685 Introduction to Deep Learning final project (Spring 2025), built with three other CMU students. The same core trio reunited in Fall 2025 for the [[2025-Fall—l43d-cad-mllm|CAD-MLLM L43D project]] — 3T3D was the DL warm-up, L43D the multimodal sequel.
Architecture
Four stages, end-to-end:
1. Input Processing
- 3 orthographic sketches representing top / side / front views (analogous to floorplan + elevations)
- Rescaled from 256×256 → 512×512 for the encoder
- Concatenated along channel dim: tensors of shape
[B, C, H, W]
2. Encoder — DINOv2 (frozen)
- Pretrained DINOv2 Vision Transformer
- Each view split into patches → patches become tokens
- Patch embeddings extracted per view
- The
clstoken is stripped (no classes in our training data)
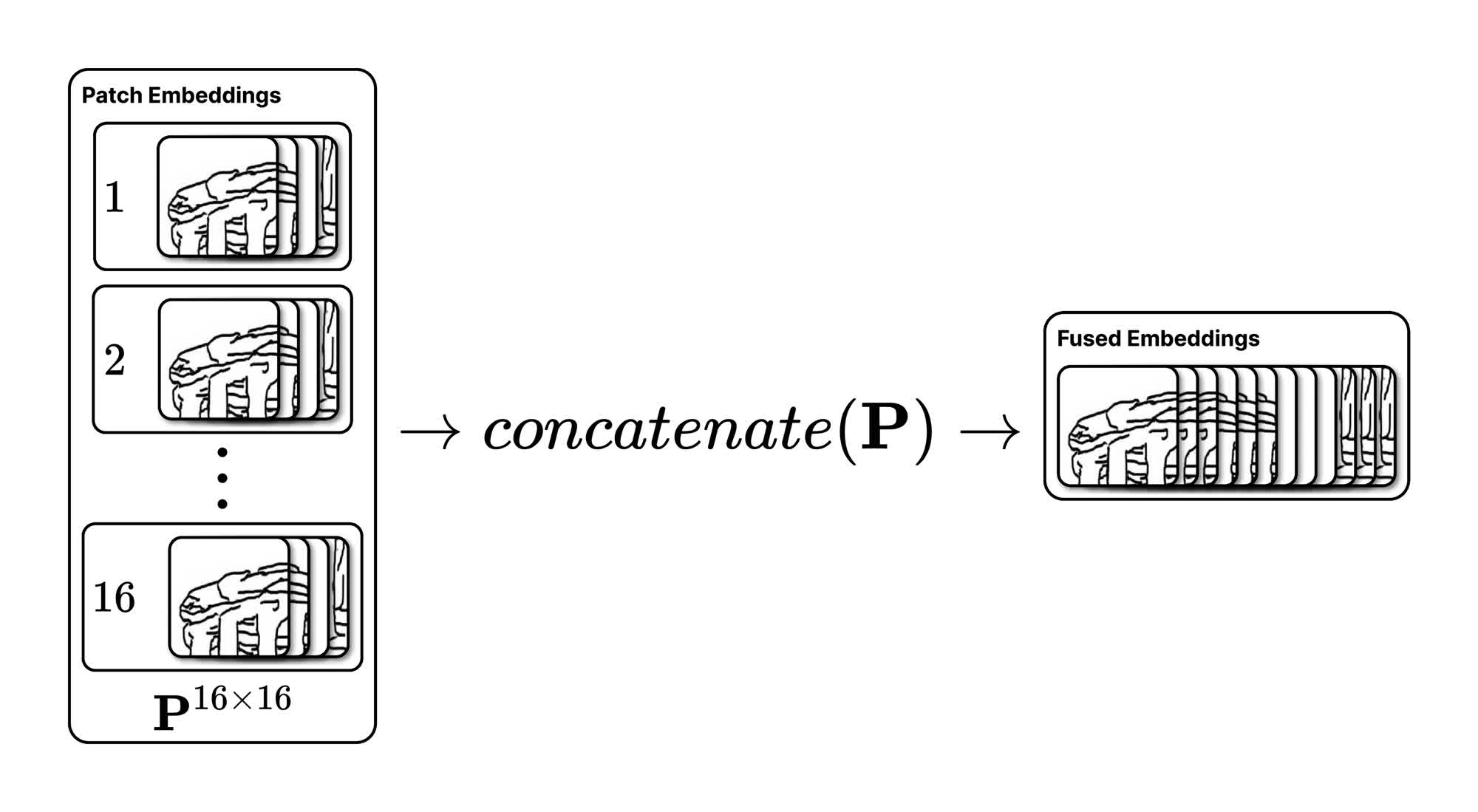
3. Fusion
- Patches from the three views that correspond to the same 3D location are summed into a single embedding
- This yields a single fused feature vector passed to the decoder
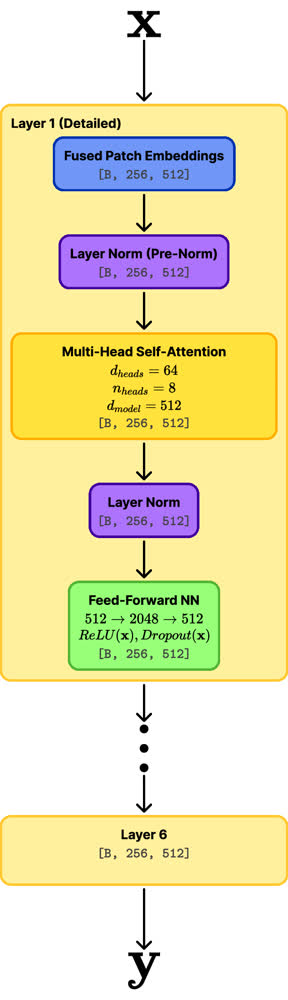
4. Decoder — Custom Transformer
- 6 decoder layers, 8 attention heads each, self-attention
- Tuned balance between runtime, model size, and output quality
5. Progressive Upsampling
- R¹⁶ → R¹²⁸ via progressive upsampling
- Output: triplane representation of the 3D object
Dataset — built from scratch
No existing dataset was suitable for architectural design quality. We built a custom pipeline:
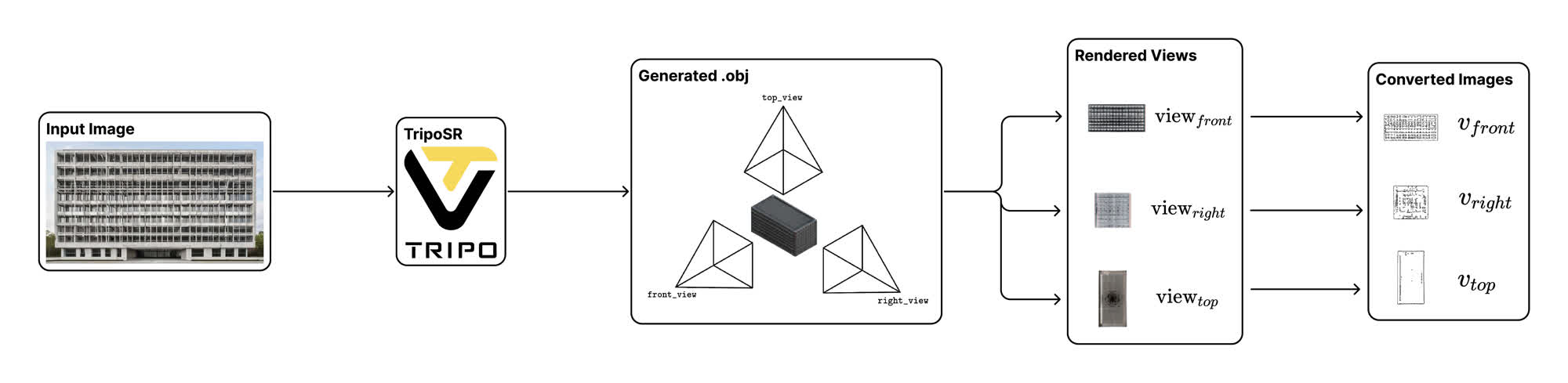
- Generate thousands of architectural renderings programmatically
- Run TripoSR on each rendering to get a 3D model
- Render top / front / side views of each 3D model
- Convert each view into a sketchy line drawing via Informative Drawings
- Result: triplets of (sketch front, sketch right, sketch top) paired with a 3D mesh (
.obj)
Dataset samples:
| Sketches | 3D Models |
|---|---|
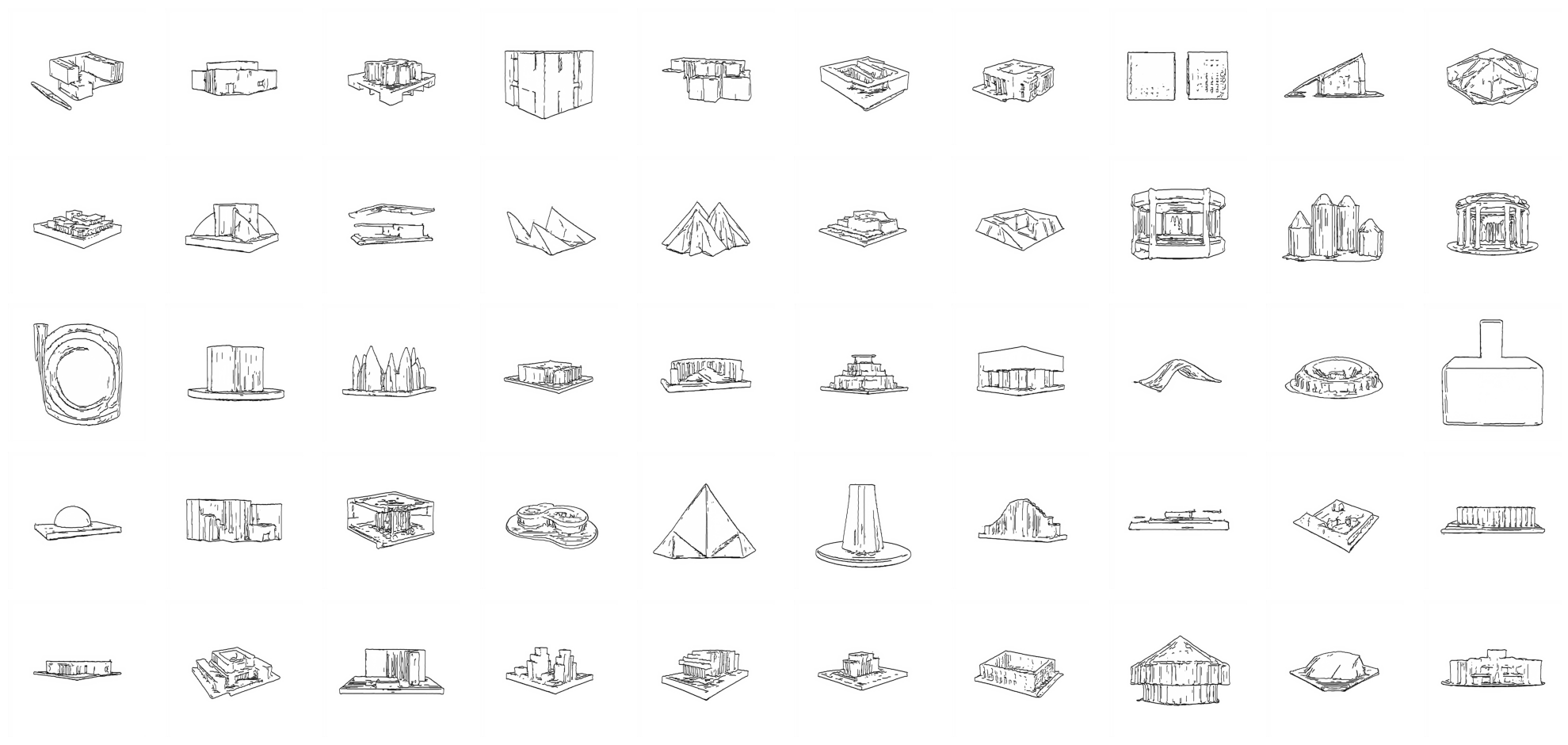 |  |
Dataset structure (public, Google Drive):
Dataset/
├── sketch/
│ ├── front/ # Front view sketches (.png, .jpg)
│ ├── right/ # Right view sketches
│ └── top/ # Top view sketches
└── 3dmodel/ # 3D meshes (.obj files)Training
- Loss: L1 between predicted triplane features and ground-truth triplane features
- Two-stage schedule:
- Freeze DINOv2 encoder; train decoder only until predictions are good
- Unfreeze entire model; fine-tune with differentiated learning rates (low for encoder, higher for decoder)
- Compute: 37 epochs on a single A100; avg ~480 s/epoch; ~5 hours total
- Tracking: Weights & Biases
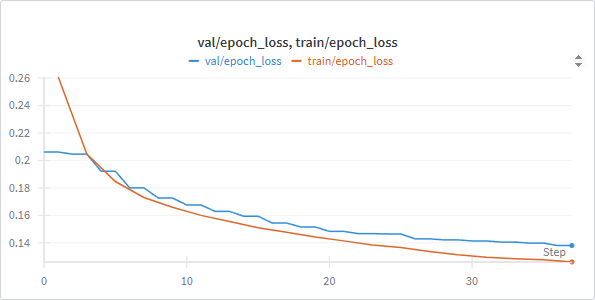
Results
Model learns triplane representations — slowly but steadily. With better LR scheduling + hyperparameter tuning, we believe the score could improve substantially. Example output vs ground truth:

Outcomes
- Novel contribution: a VT-based, 3-view sketch-to-3D model specifically for architectural design — not just object-level like most prior 2D→3D work
- Custom dataset pipeline (architectural renderings → TripoSR → sketchy views → triplane 3D) is reusable
- Published dataset on Google Drive
- Final writeup in vault at
/assets/3t3d-vit-2d-to-3d/3t3d_writeup.pdf(1.8 MB, 2025-04-28 final) - Final presentation video on YouTube
- Flagship portfolio piece — David’s most substantial ML systems work alongside [[2025-Fall—l43d-cad-mllm|L43D CAD-MLLM]]; pairs nicely since they share 3/4 team members and continue the same “designer-facing generative 3D” thread
David’s contributions
From WhatsApp chat evidence + team discussion:
- Literature review: shared CLIP, TripoSR, DINOv2 papers (arXiv:2109.14124, arXiv:1807.06358)
- Dataset management — David provisioned + shared Google Drive folders on 2025-03-29 and during iteration
- Overleaf report co-authoring (team explicitly called David “our overleaf master”)
- Reference-research + experiment tracking
(David’s GitHub commits don’t all attribute to his chentianle1117 username — Colab sessions often commit under alt identities.)
Reference lineage
| Reference | Use |
|---|---|
| DINOv2 (arXiv:2304.07193) | Encoder backbone |
| TripoSR (arXiv:2311.04400) | Dataset generation |
| Informative Drawings | Sketch conversion |
| pix2pix3D | Related-work baseline |
| Triplane representations (arXiv:2302.08509) | Output representation |
| CLIP | Considered for early pipeline |
| Hunyuan3D-2 | Considered |
| TriplaneGaussian | Considered |
Artifacts in vault
Under Portfolio//assets/3t3d-vit-2d-to-3d/:
| File | Size | Purpose |
|---|---|---|
3t3d_writeup.pdf | 1.8 MB | Final project writeup (pulled from repo /img/) |
project_notebook.ipynb | 5.1 MB | Final project notebook (from team WhatsApp) |
dev_triplane.ipynb | 1.7 MB | Triplane representation development notebook |
dev_with_validation.ipynb | 2.9 MB | Training + validation notebook |
arch_diagram.jpg, fusion_diagram.jpg, decoder_diagram.jpg | — | Architecture figures |
dataset_creation1.jpg, data_sketch.png, data_3d.png | — | Dataset pipeline + samples |
val_train_loss.png | — | Wandb training curves |
comparison.jpg | — | Model output vs ground truth |
Links
- GitHub: chentianle1117/3T3D — David’s personal fork (primary link for portfolio; preserves the project under his name)
- GitHub: 1gfelton/3T3D — upstream canonical public repo on Graham’s account (READMEd, polished for public use, writeup PDF)
- GitHub: 11-685-Team-52/3Ts-Model-for-Architectural-design-process — team’s shared working repo with 3 notebooks:
3_2d_to_3d_w_validation+dataaug_2504.ipynb(29 MB, late-iteration data-augmentation version),ImageGEN-Chia.ipynb(1.1 MB — Chia’s dataset pipeline),triplane_encoder_decoder.ipynb(74 KB) - Final video presentation (YouTube)
- Public dataset (Google Drive)
- Final writeup PDF (in vault):
/assets/3t3d-vit-2d-to-3d/3t3d_writeup.pdf - Overleaf report source: https://www.overleaf.com/project/680ad1d4af18bc319d37a756
Related cards
- [[2025-Fall—l43d-cad-mllm]] — same core trio (David + Chia + Karthick) + Yizhuo Di, extending the generative-3D arc into multimodal CAD