Team 21’s unofficial reproduction + extension of CAD-MLLM (arXiv:2411.04954). A unified CAD generation system that accepts text, point cloud, image, or any combination as input — and outputs editable CAD models. David’s contribution: the autocompletion extension — generating full CAD sequences from partial ones via intelligent truncation.

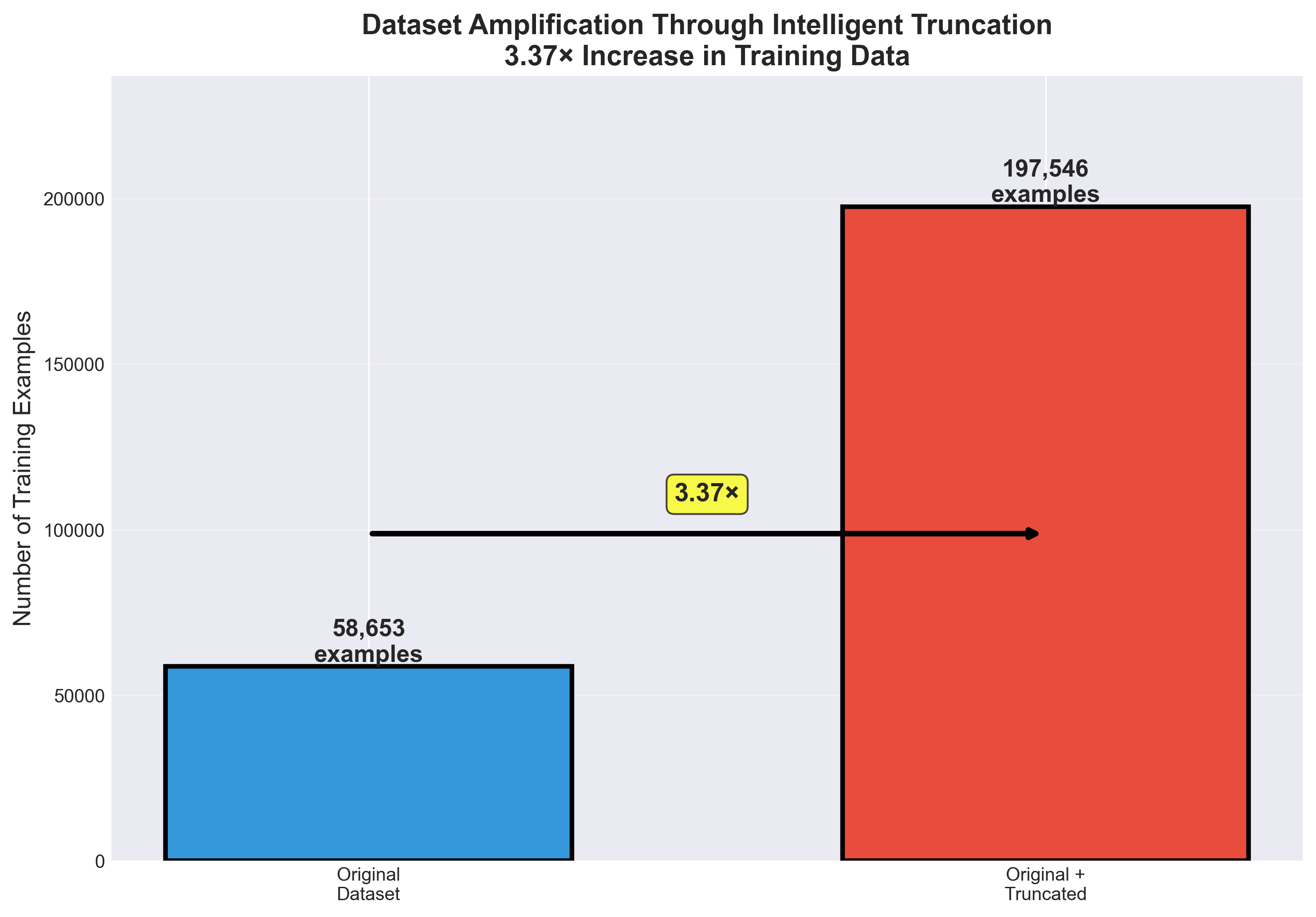
One LLM, three modalities — text, point cloud, image — and any combination of the three. We fine-tuned Vicuna with LoRA on a 10% DeepCAD subset amplified 3.37× through an Intelligent Truncation algorithm that generates valid partial CAD sequences by recursively tracing entity dependencies. The result: 197,546 training examples covering all modality combinations, ~60% STEP-file generation success, and >70% CAD-sequence accuracy on the outputs that compiled.
The project was the 16-825 Learning for 3D Vision final (Fall 2025), built with three other students at CMU. My specific contribution was the autocompletion extension on the autocomplete and autocomplete_2 branches — dynamic masking during training so the model learns to complete partial CAD sequences. The fine-tuned weights are published as chentianle1117/autocomplete-stage3-8000 on HuggingFace.
Dataset — 3.37× amplification via intelligent truncation
The original CAD-MLLM paper’s dataset doesn’t include point clouds, multi-view images, or partial-sequence pairs. Team 21 rebuilt the dataset from scratch:
- Start from 10% DeepCAD subset (58,653 CAD models)
- Use OpenCascade to generate:
- STEP files (editable CAD format)
- Point clouds (sampled from surface)
- Multi-view renders (missing modalities in DeepCAD)
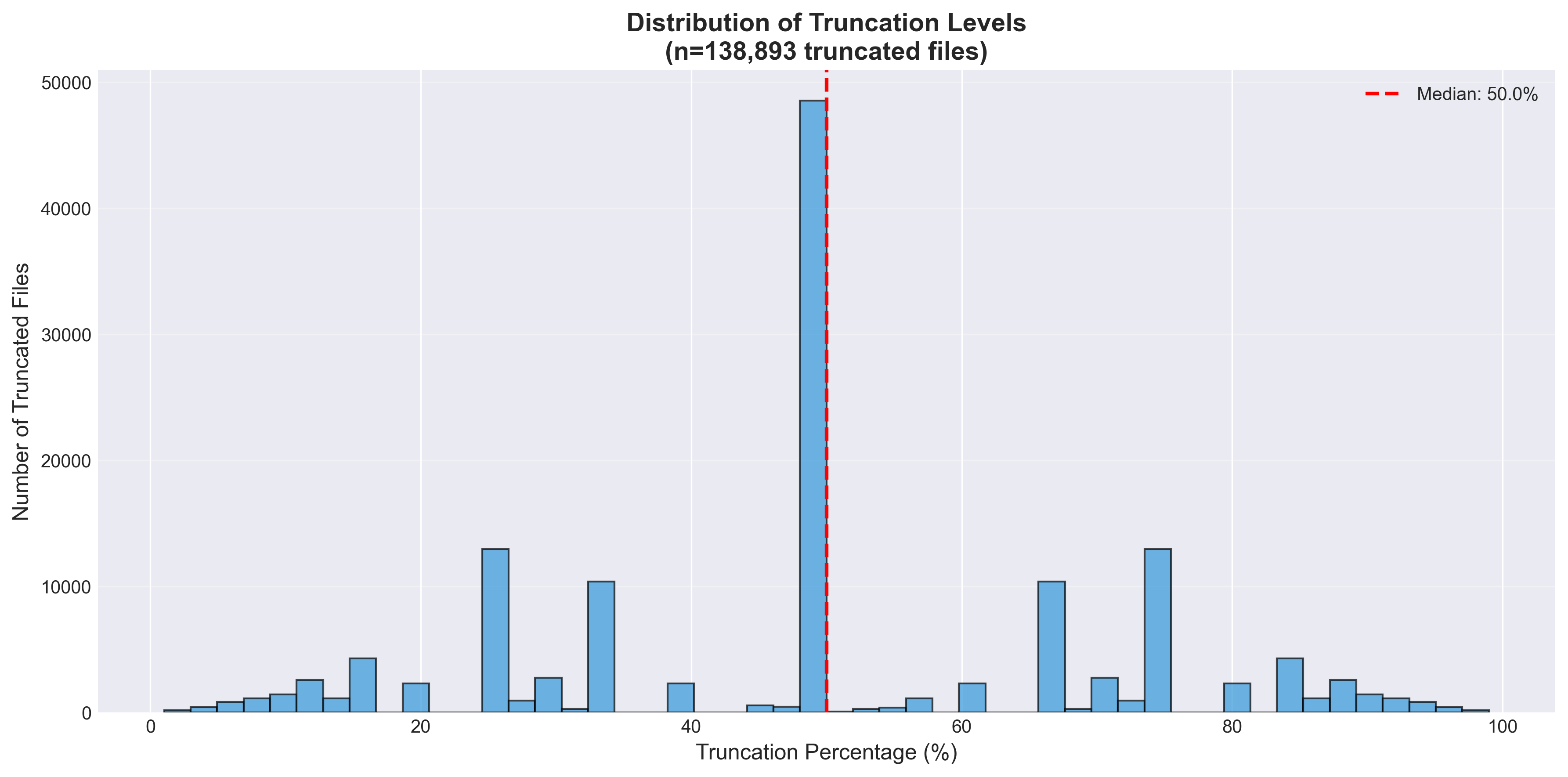
- Intelligent Truncation algorithm — recursively trace entity dependencies; identify operation boundaries; generate partial sequences where every truncated sequence is geometrically consistent (all referenced entities preserved)
- Result: 58,653 → 197,546 training examples across all modality combinations (3.37× amplification)
Methodology — multimodal projection + LoRA-tuned Vicuna
The network handles three single modalities or any combination. Architecture:
- Per-modality frozen encoders — each modality (point cloud, image) goes through its own pre-trained encoder
- Trainable projection layers — project each modality’s embedding into the LLM’s language feature space
- Vicuna LLM with LoRA — fine-tuned with Low-Rank Adaptation on the projected embeddings + text prompt
- CAD output — model emits a CAD JSON sequence that can be converted back to STEP files
Training configuration:
modality_sample_probs = {"text": 0.2, "text+point_cloud": 0.3, "text+image": 0.2, "text+point_cloud+image": 0.3}max_seq_length = 4096- Three-stage curriculum: text only → text + point cloud → text + point cloud + image
Evaluation
Eval settings (eval_id, checkpoint, max_new_tokens, input modality):
- Eval 1 —
checkpoint-epoch0-step140-20251128_072200, 10,240 tokens, text only - Eval 2 — same checkpoint, 2,048 tokens, text only
- Eval 3 —
stage-epoch0-step100-20251128_220651, 4,096 tokens, image + point cloud + text - Eval 4 —
stage-3-4096-20251128_2158, 4,096 tokens, image + point cloud + text
Topology evaluation metrics:
- STEP/raw conversion rate — % of outputs that successfully compile to a valid STEP file
- DangEL (Dangling Edge Length) — length of unclosed boundary edges
- SIR (Self-Intersection Ratio) — % of self-intersecting faces
- FluxEE (Flux Enclosure Error)
CAD Sequence metrics:
- Entity Count Acc (1.0 = perfect match)
- Type Seq Acc — accuracy of type sequence (1.0 = perfect)
- Type Dist Sim — Jaccard similarity on entity-type distributions
Results:
| Eval | Input | STEP conversion | Notes |
|---|---|---|---|
| 1 | Text only, 10,240 tok | 40% (8/20) | |
| 2 | Text only, 2,048 tok | 90% (45/50) | best topology |
| 3 | PC + Image + Text, 4,096 tok | 33.3% (5/15) | |
| 4 | PC + Image + Text, 4,096 tok | 60% (9/15) | best multimodal |
Summary finding: STEP success rate is higher with text-only input (simpler outputs compile more reliably), but CAD sequence accuracy improves significantly with multimodal input — richer information produces higher sequential fidelity. Overall pipeline: ~60% average STEP success, >70% CAD-sequence accuracy on successful outputs. Current limitation: simple shapes only, due to small training-data size + short text prompts.
Outcomes
- Unofficial-but-working reproduction of a major CVPR-track multimodal CAD paper
- Novel technical contribution — Intelligent Truncation for autocompletion (David’s branches); rebuilt DeepCAD with modalities it originally lacked
- Published model on HuggingFace:
chentianle1117/autocomplete-stage3-8000 - Team poster presented at L43D poster session, 2025-12-04
- Full final report delivered (see
/assets/l43d-cad-mllm/final-report.pdf) - Flagship portfolio piece — David’s most substantial ML systems work to date; demonstrates multimodal LLM fine-tuning, dataset engineering, evaluation metric design, distributed training infrastructure
Artifacts in vault
All committed under Portfolio//assets/l43d-cad-mllm/:
| File | Size | Note |
|---|---|---|
poster.pdf | 5.1 MB | Final 36×36″ poster (Team_21_Poster.pdf from WhatsApp 2025-12-03) |
final-report.pdf | 11.5 MB | Final report |
proposal-final.pdf | 313 KB | Final project proposal |
proposal-v1.pdf | 161 KB | Original proposal |
combined_summary.png | — | Poster figure: combined summary |
data_amplification.png | — | Poster figure: dataset amplification |
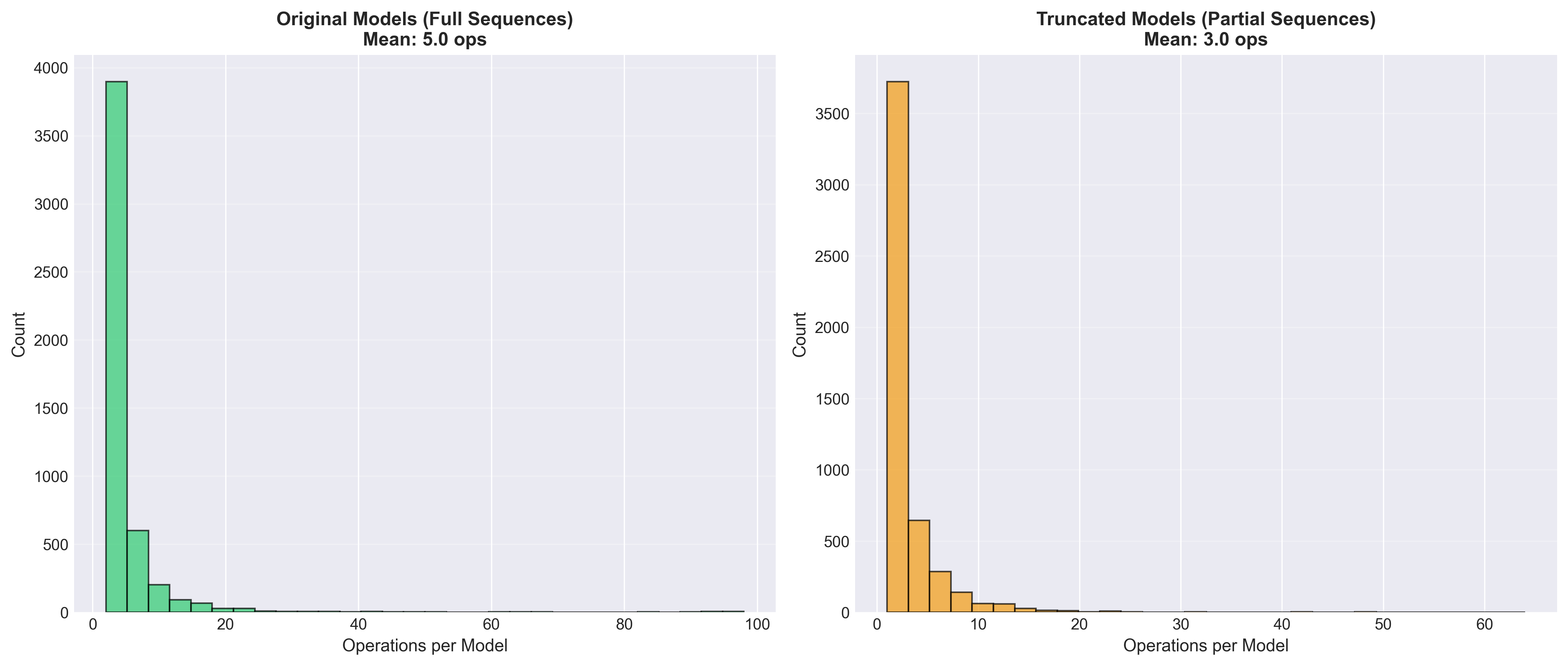
operations_comparison.png | — | Poster figure: operations comparison |
truncation_distribution.png | — | Poster figure: truncation distribution histogram |
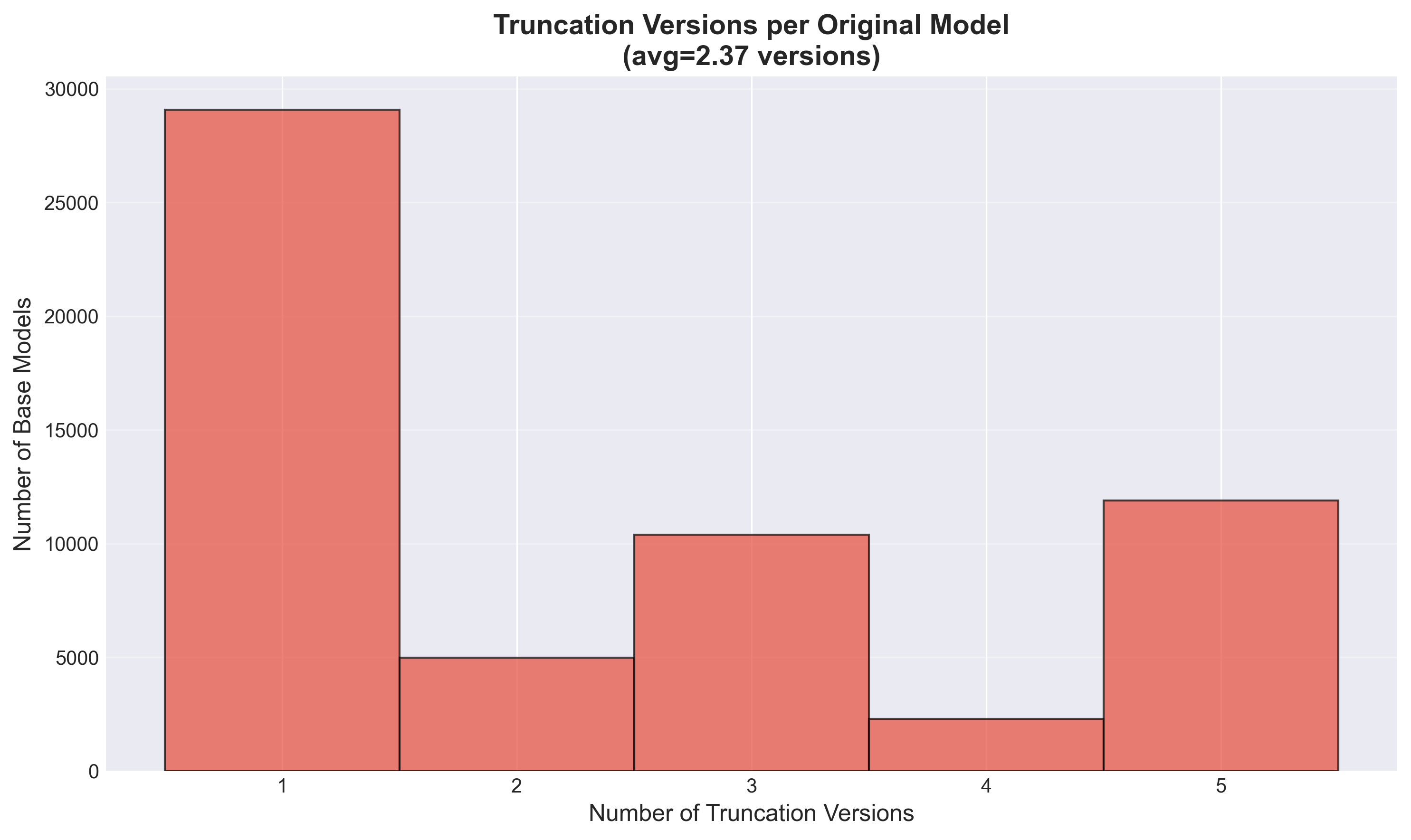
versions_per_model.png | — | Poster figure: versions per model |
Links
Code:
- David’s personal fork: chentianle1117/CAD-MLLM-unofficial — primary portfolio link (preserves project under David’s name)
- Upstream: veoery/CAD-MLLM-unofficial — canonical team repo on Yizhuo’s account
- David’s branches:
autocomplete·autocomplete_2
Models + data:
- HuggingFace org:
omnicad-lab-L3d - David’s model:
chentianle1117/autocomplete-stage3-8000 - Dataset:
omnicad-multimodal-subset-fast
Docs:
References (team-cited during development):
- DeepCAD (rundiwu/DeepCAD) — upstream dataset
- Brep2Seq (zhangshuming0668/Brep2Seq) — architecture reference
Note on Figma
Team used a Figma board for poster design (Ethan / Yizhuo invited by email on 2025-12-01). The URL wasn’t captured in the WhatsApp chat transcript — only an email-invite flow. If you still have Figma access, paste the URL and I’ll add it to the frontmatter.